How to Normalize Data in Microsoft Access
Microsoft Access, Microsoft Office
The term “normalization” gets thrown about quite a bit in database circles, to try to explain part of data organization. But it’s vague, to someone not acquainted with database-ese.
The idea of making data “normal” is not too far from the meaning used by database designers. What’s “normal?” When we create, say, a batch of file cards with names, addresses, etc., we tend to lay out the information similarly—consistently—so as to make it easier to follow on each. If each piece of information is in its own place, a “field” or space designated for each, we’re already close to the idea of normalization. One wouldn’t want to put the first and last name in the same field, since we might want to sort by last name first. We couldn’t do it easily if the two were in the same place. Nor would we want to put street address, city, state, and zip code in the same field, for the same reason.
So one rule we try to follow regardless of what kind of database software we use, MS Access for example, is “one piece of information per field”. If one wanted to fill a glass jar’s volume completely, using something like golf balls would not work too well. They’re too big to really follow the shape of the jar. But using gravel, or sand, or better still, flour, would be better. The individual pieces are smaller, and can fit the space much better. The smaller the pieces, the more “flexible” they are in filling the space. This is how we start to normalize.

Secondly, it’s a good idea to divide the tables (or collections of data) into categories. An employee database might contain tables of personal data, office data, health plan data, travel/transport data, etc. It’s easier for most databases—and users—to work with a larger number of smaller tables than the other way round.
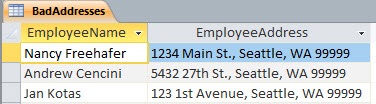
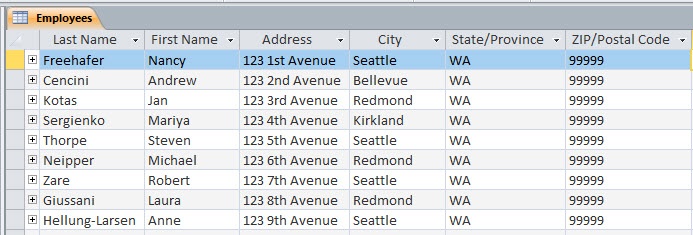
Finally, there is at least one exception. Some kinds of data, such as addresses, work better with a little de-normalization. (Access makes this fairly easy to see.) We don’t want to put a zip code in the same field with city and state. But putting city, state, and zip fields in an address table—even though slightly redundant—make the addresses easier to handle.
To learn more, try out our Access classes.