How to Use Table Joins in Microsoft Access
Microsoft Access, Microsoft Office
The use of table relationships in Access allows tables to cooperate in the use of data, but table joins, while they look similar, serve a different purpose. The relationships, which allow coordination while organizing data, nevertheless don’t directly affect, say, the results of a query. Joins do.
A table join in a query allows for a filter effect. The thinking is that a query is a question one asks of the database. But redundant answers are no use, and a waste of space. So when we pull data from more than one table, frequently the case, we don’t want repeat answers, or every possible permutation of the answers/data.
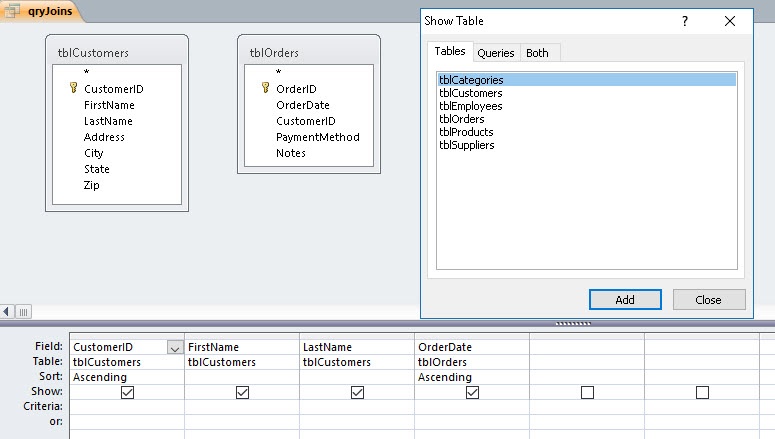
When creating the query, we choose the tables (assuming we need more than one, which is normal) and insert them.
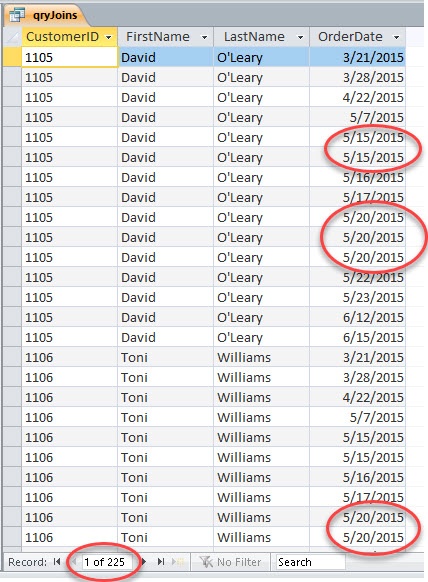
If we run the query without a join, we get every possible combination of the field data for an answer…which often leads to repeat results.

So we decide which field(s) to use in the join (the nature of the database tells us about this). And we specify the join—usually an “inner” join, which shows only results both tables share. We create the join the same way as we create a relationship. We drag from a field in one table to its counterpart in the other. The main difference to the program is, the join only activates when the query runs, saving time and memory usage. And some joins are only useful at certain points in the database’s operation. So creating a permanent relationship outside the query is unnecessary.
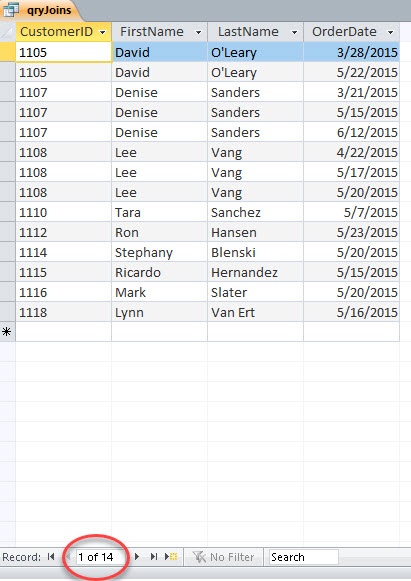
When we run the query with the join, to filter out repeats, the number of answers becomes more reasonable. We can use a key field as one of the query result fields, which certainly cuts down on repeats. It has the same effect in a query as it has in a database in general—unique identification of a record. But the key point is, table joins will “insist” on reducing repeats, and even more with a key field involved.
Usually, very few business database-related queries will have no repeat results—the data are such that this seems almost impossible. But if we can eliminate 95+% of repeats, only the most massive sets of results will have them.
To learn more, take a look at our Microsoft Access classes.