Using the Three Normal Forms in Microsoft Access
Microsoft Access, Microsoft Office
One of the more abstruse points of procedure in Access involves the three so-called normal forms. What, exactly, are they? If you think “guidelines”, or “protocols”, you’d be in the ballpark.
When building a database, especially a relational database, there are some “streamlinings” which allow it to function more efficiently. Knowing the how is important, but the why can be too. “Why” is what I’d like to go over here.
The first of the normal forms is basically this: In any field, in any record of the database, there should be one and only one piece of information. The simplest examples are things like phone numbers.
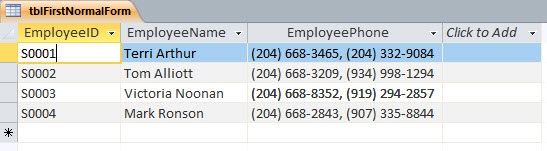
Since today computers can be hooked up to, and can dial, phones, if two numbers are in one field, the computer might not be able to tell which one to dial, or it might think they were one long number. And that would mess the process up.
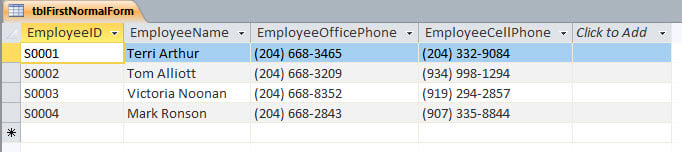
It also allows easier querying, filtering, and other kinds of analysis of data. Another common example is entering addresses: If the street address, city, state, and Zip code are all in one field, sorting or filtering by any of those would be much more difficult. But give each one a separate field, and it’s quite straightforward. This is part of what we call normalization. If the data are divided into the smallest pieces which still have meaning, you have raw ingredients in the kitchen. You can do more with those than, say, premixed pancake batter, which is pretty much only good for pancakes.
The second of the normal forms is about key fields—the ones that act as unique IDs for each record, in tables which need them. (The usual example here is a Social Security number, or employee ID number, or SKU number for merchandise.)
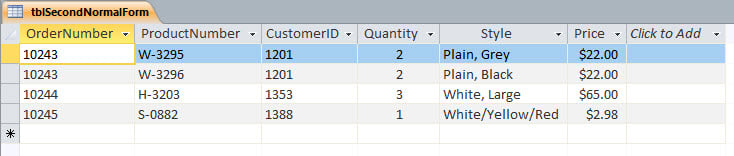
It is possible for a table to have two, or more, key fields per record, and occasionally this is necessary (as in a table of merchandise orders). But the uniqueness should then depend on the entire set of key fields (a composite key), not just one, because otherwise it will be possible to have duplicate data in the table, and this is a major no-no. (This is basically the second normal form.) Duplicate info wastes space, and can confuse query results. If any of the fields’ data don’t depend on the whole key (multiple fields), they should be in another table.
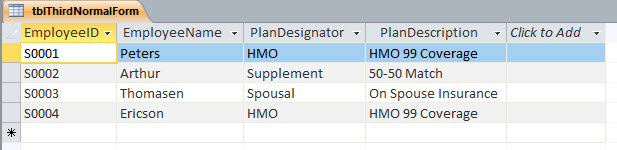
The third of the normal forms is a little more complicated to explain. But the point is simple: Redundant information should be in a separate table. One situation in the real world has to do with employee databases including health plan info. There’ll be a number or letter indicating which plan someone is on. Then, in the next field, the name of the plan. But if these are the same each time, why not use just the letter in the employee table, and put the detailed information in another table? It reduces the amount of typing someone has to do, and simplifies the table in question.
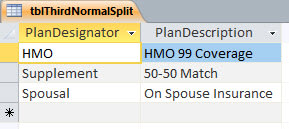
It also offers a hidden benefit. If one puts the letters for the plans in another table as the primary key, and has plan names or other data in other fields in that same table, changing data in the plan table will affect everyone who uses the plan letters at once. So the subset of data regarding plan details is centralized, and can easily be changed for everyone with a minimum of work. So a sort of corollary to the third normal form is, one kind of data per table (if redundant data is a second kind per table, this falls into place pretty neatly).
One piece of info per field; one key field per table where possible, and use all the key fields for ID if not; split off redundant data to another table, which also offers easier changes to some kinds of data. Those are the essentials of the normal forms. There are other data models, and other operating ideas. But since Access is so common, understanding how to make it run better is good.
To get a better idea of this, take a look at our Microsoft Access training.